Manage HDFS Storage — Sync and Backup Files with RcloneView

Hadoop clusters hold years of processed data, but moving that data between on-prem storage and the cloud usually means dropping into scripts and CLI tools — RcloneView gives HDFS a visual home instead.
Hadoop Distributed File System (HDFS) is the storage layer behind countless on-premise big data pipelines, but it doesn't come with a friendly way to inspect, transfer, or archive that data outside the Hadoop ecosystem. RcloneView connects to HDFS as a protocol-based remote alongside SFTP, FTP, and WebDAV, so a data engineer can browse cluster contents in a familiar file explorer and move datasets to and from cloud storage without writing a distcp job or a custom script. It runs the same on Windows, macOS, and Linux, which matters when your data team isn't all on the same operating system.
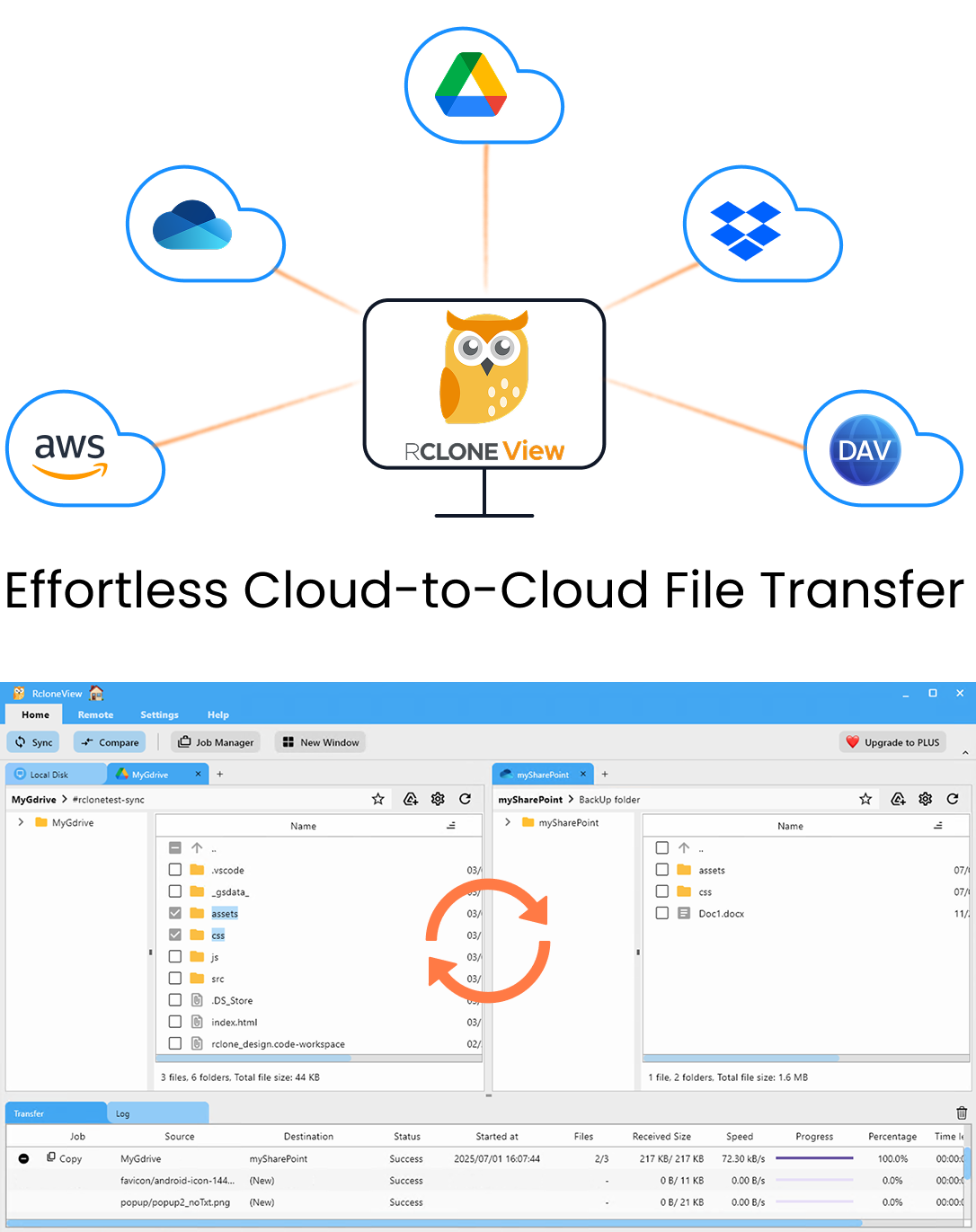
Manage & Sync All Clouds in One Place
RcloneView is a cross-platform GUI for rclone. Compare folders, transfer or sync files, and automate multi-cloud workflows with a clean, visual interface.
- One-click jobs: Copy · Sync · Compare
- Schedulers & history for reliable automation
- Works with Google Drive, OneDrive, Dropbox, S3, WebDAV, SFTP and more
Free core features. Plus automations available.
Adding an HDFS Cluster as a Remote
HDFS falls under RcloneView's protocol-based storage category, configured through the same New Remote wizard used for SFTP and WebDAV connections. Once the cluster is added, it appears as its own tab in the Explorer panel, with the standard folder tree, file list, and thumbnail view available for browsing datasets stored across the cluster's namenodes. Right-click operations — copy, download, rename, Get Size — work exactly as they do on any other remote, which means engineers who aren't comfortable with hadoop fs commands can still audit what's actually sitting in HDFS.
RcloneView mounts AND syncs 90+ providers from one window, so the same session that browses HDFS can have a Google Drive, S3 bucket, or local disk open in an adjacent panel for direct comparison.
Bridging On-Prem Storage with Cloud Object Storage
The most common reason to connect HDFS to RcloneView is moving cold or processed data out of an expensive, capacity-constrained cluster and into cheaper cloud storage for long-term retention. A one-way sync job with "Modifying destination only" direction copies HDFS output — processed datasets, model training artifacts, log archives — to an S3, Azure Blob, or Backblaze B2 bucket without touching the source. Filtering settings in Step 3 of the sync wizard let you scope the job to specific file types or exclude intermediate _SUCCESS and temp files that Hadoop jobs leave behind, so the destination bucket only holds what's actually worth keeping.
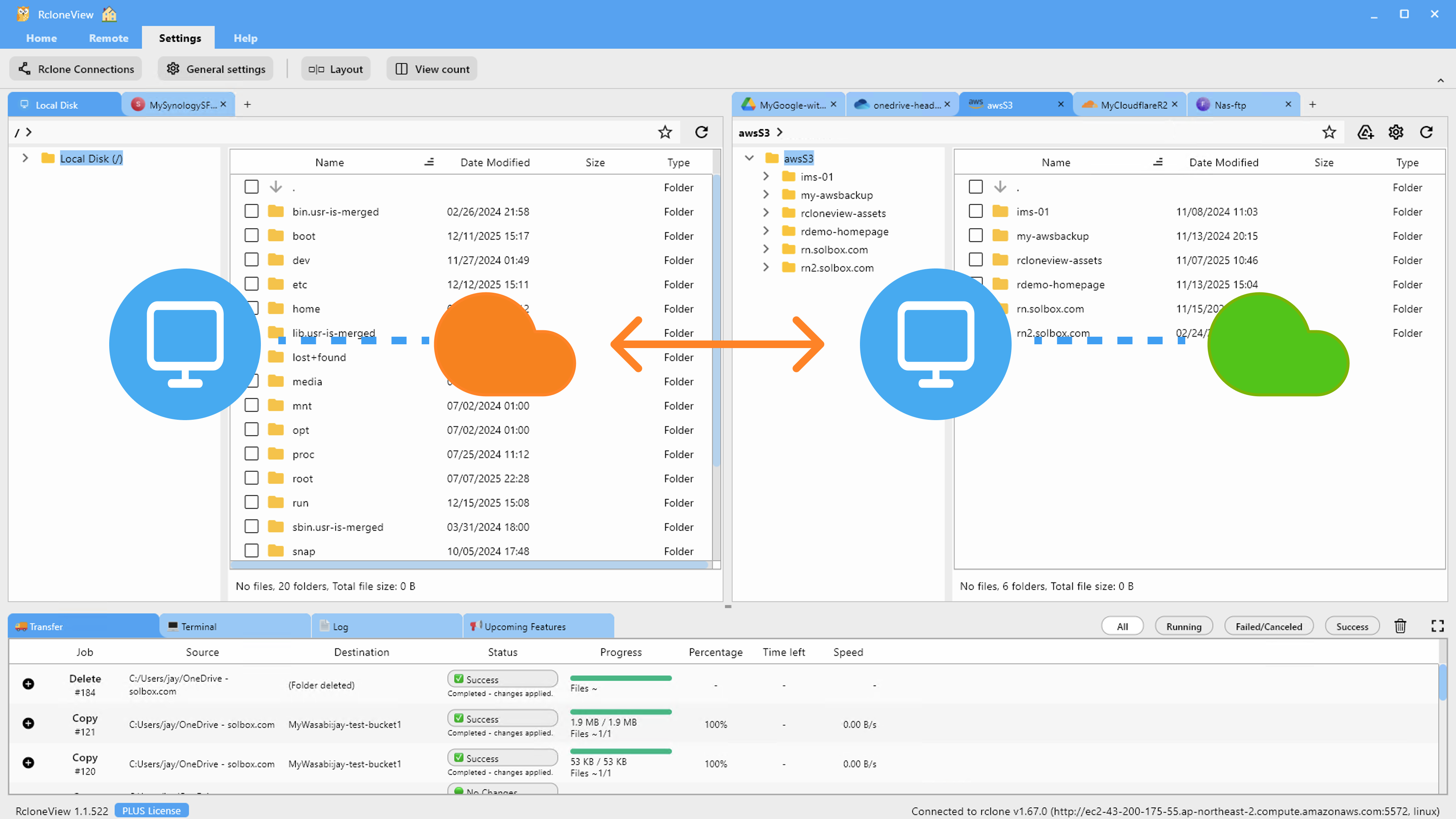
For large datasets, tuning the number of file transfers and multi-thread transfer count in Advanced Settings helps saturate available bandwidth between the cluster and the destination, while keeping the number of equality checkers modest avoids putting unnecessary read load on the namenode during the comparison phase.
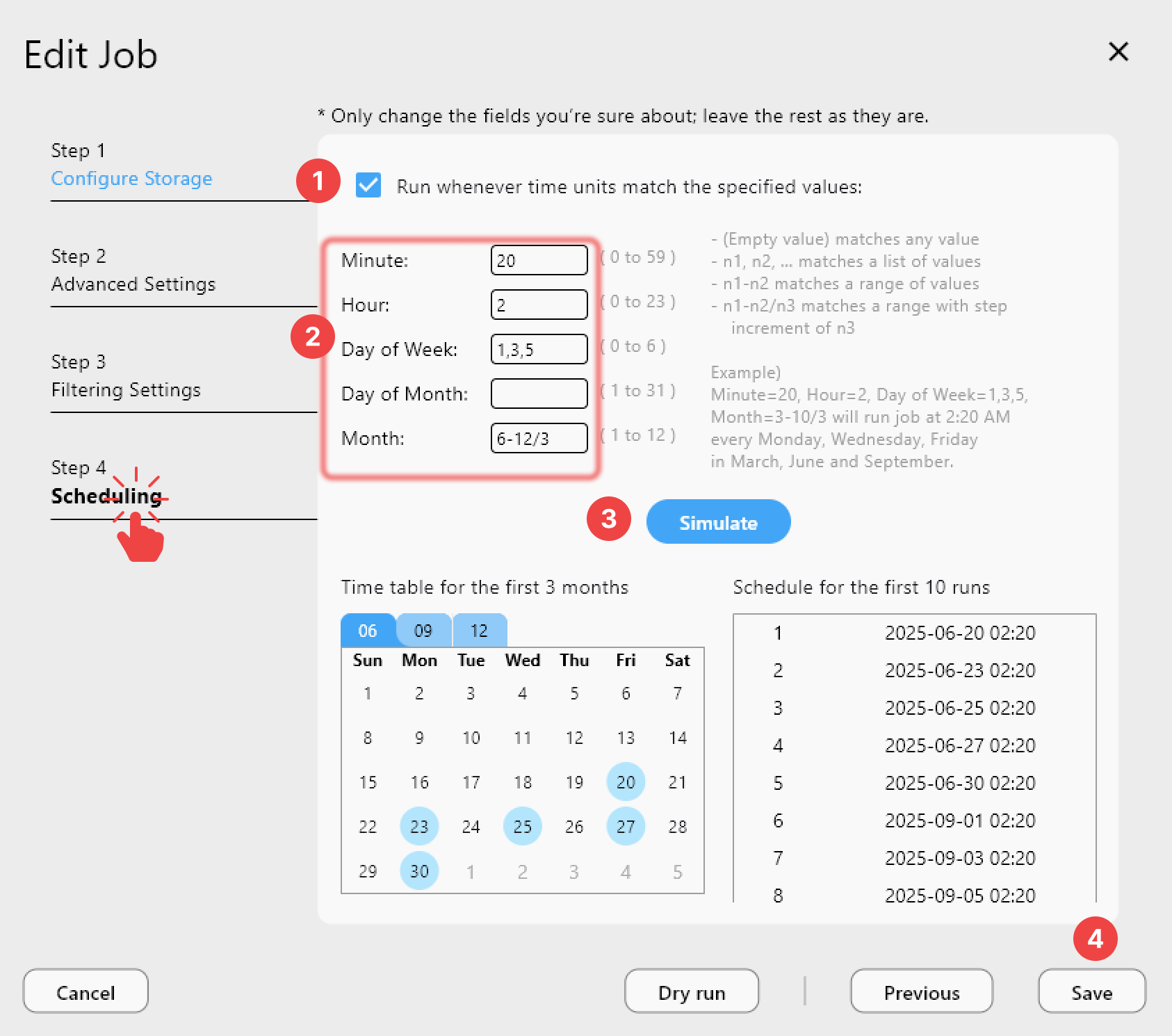
Scheduling Recurring Archival Jobs
Data pipelines rarely run once. PLUS license users can attach a crontab-style schedule to an HDFS sync job so newly landed output gets mirrored to cloud storage automatically after each batch run, rather than requiring someone to remember to kick off a manual transfer. Job History then tracks every execution — status, size transferred, duration — giving the team an audit trail that shows exactly when each dataset left the cluster and where it landed.
Getting Started
- Download RcloneView from rcloneview.com.
- Add your HDFS cluster as a new remote using the protocol-based storage option.
- Browse the cluster in the Explorer panel to confirm datasets and permissions look correct.
- Set up a one-way sync job to your archival cloud destination, with filters to exclude temp files.
Bringing HDFS into the same window as your cloud remotes turns a scripted, error-prone export process into a repeatable job you can monitor and schedule.
Related Guides:
- Manage MinIO Storage — Self-Hosted Cloud Sync in RcloneView
- Cloud Storage for Data Scientists — Streamline Datasets with RcloneView
- AI Training Dataset Pipeline — Build and Sync with RcloneView