How to Recover Interrupted or Failed Cloud Transfers with RcloneView
Network drops, API timeouts, laptop sleeps, and power outages interrupt cloud transfers. RcloneView and rclone have built-in mechanisms to resume safely without re-uploading everything from scratch.
Transferring terabytes to the cloud is not a five-minute operation. During long-running jobs, connectivity interruptions are almost inevitable. The good news is that rclone's intelligent transfer engine — which RcloneView uses under the hood — is designed for exactly this scenario. Copy and Sync operations are inherently idempotent: re-running them skips files already transferred and resumes from where things broke.
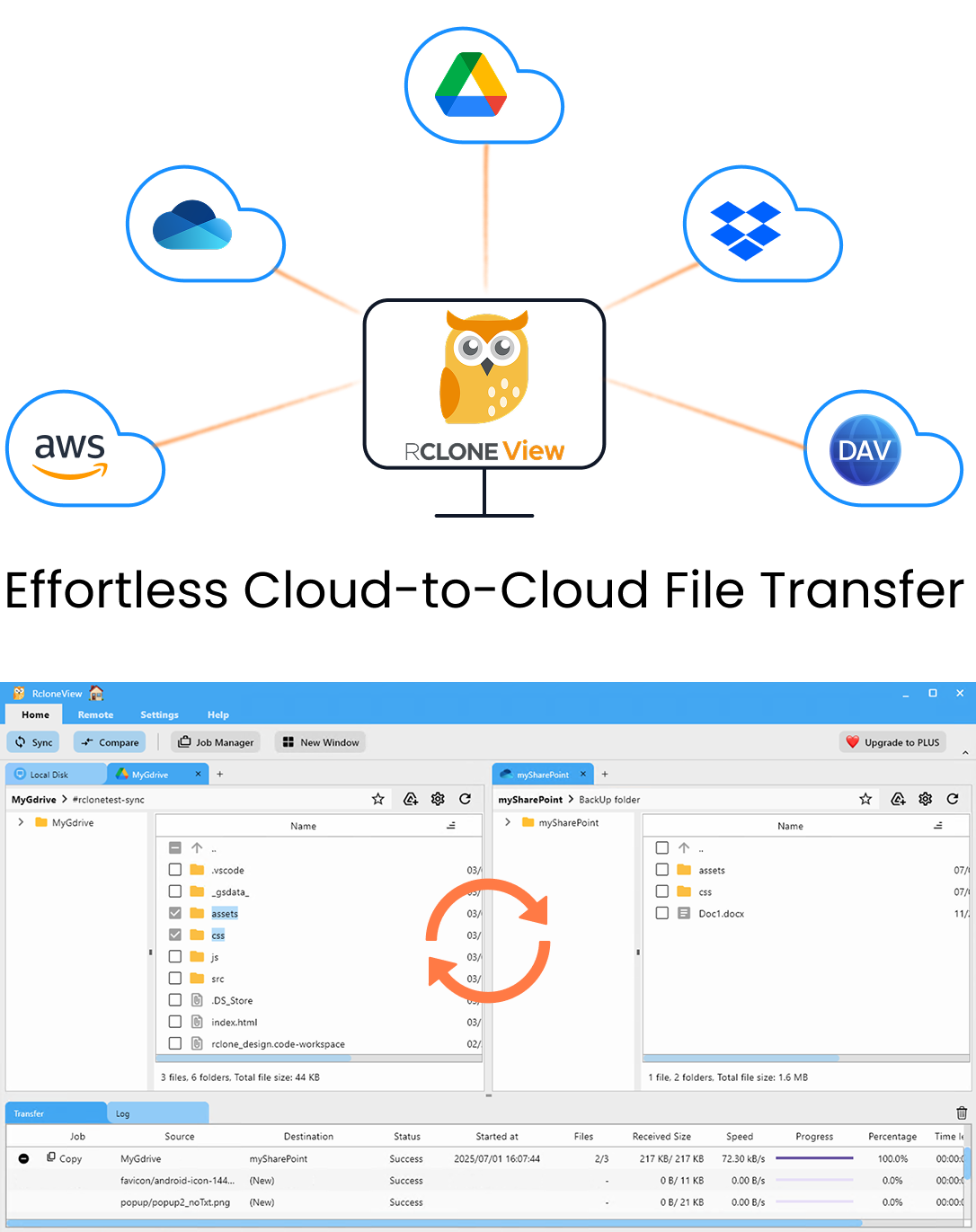
Manage & Sync All Clouds in One Place
RcloneView is a cross-platform GUI for rclone. Compare folders, transfer or sync files, and automate multi-cloud workflows with a clean, visual interface.
- One-click jobs: Copy · Sync · Compare
- Schedulers & history for reliable automation
- Works with Google Drive, OneDrive, Dropbox, S3, WebDAV, SFTP and more
Free core features. Plus automations available.
How Rclone Handles Interrupted Transfers
Rclone compares source and destination before transferring each file. When you re-run a Copy or Sync job after an interruption:
- Files already transferred are skipped (by size+modification time, or checksum if enabled).
- Partially transferred files are cleaned up and re-transferred from the beginning.
- Not-yet-started files are queued and transferred in the resumed run.
This means there's no special "resume" button in most cases — just re-run the same job.
Step 1 — Re-Run the Same Job
After an interruption, open Jobs in RcloneView and click Run on the same job again:
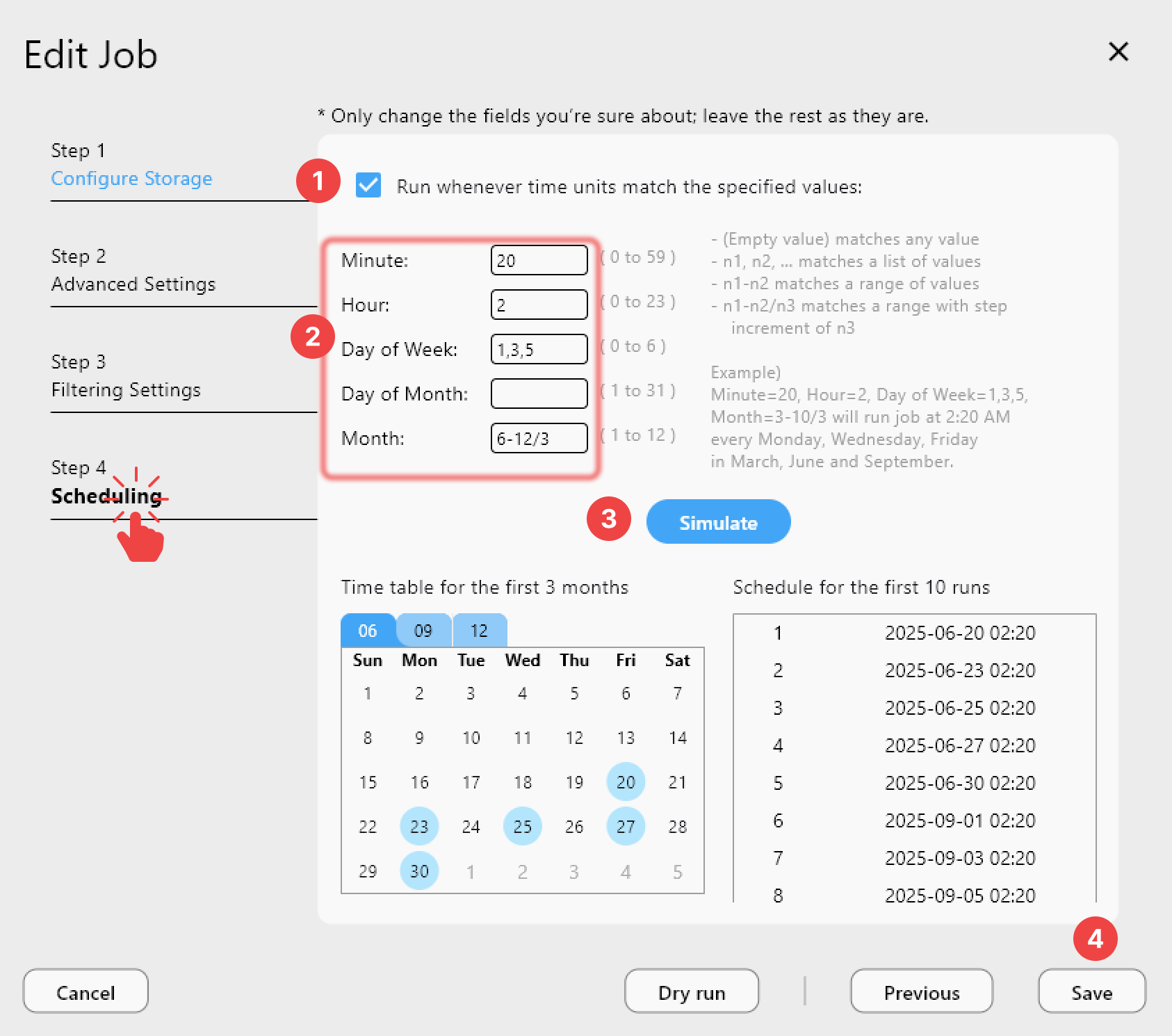
RcloneView will:
- List the source and destination.
- Compare files already present in the destination.
- Skip successfully transferred files.
- Transfer only missing or modified files.
For a 10,000-file job where 8,000 succeeded, re-running takes a fraction of the original time.
Step 2 — Check Job History for Failed Files
Before re-running, review the Job History in RcloneView to understand what failed:
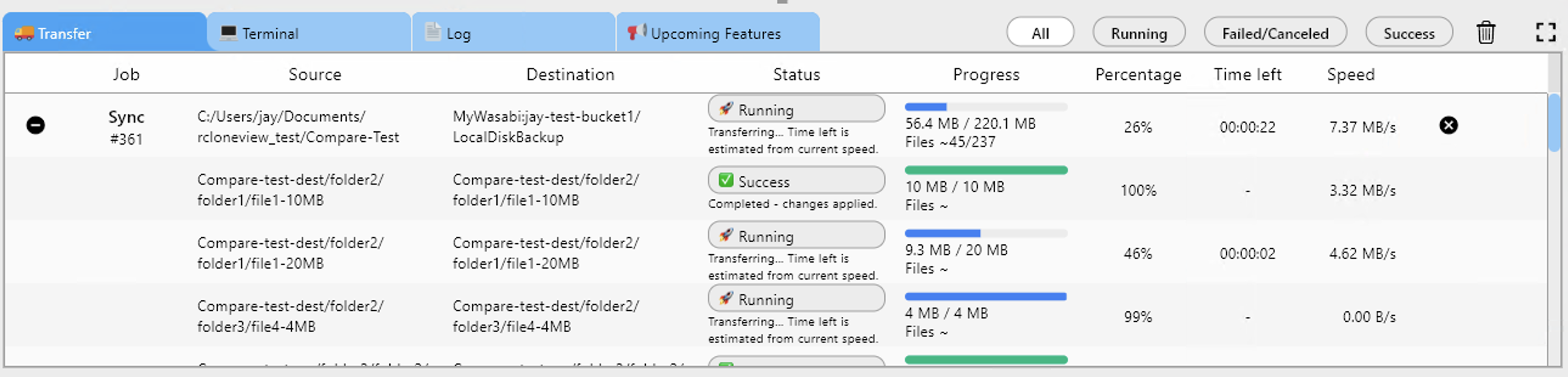
The log shows:
- Which specific files failed
- The error message for each failure
- Whether failures were transient (network error) or persistent (permissions, path too long)
Persistent errors need a fix before re-running — transient errors will resolve on retry.
Step 3 — Handle Partially Uploaded Large Files
For very large files (multi-GB), an interruption mid-upload leaves a partial file in the destination. Rclone's behavior depends on the provider:
| Provider | Partial File Behavior |
|---|---|
| Amazon S3 / S3-compatible | Multipart uploads: incomplete parts are orphaned, rclone retries from scratch |
| Google Drive | Resumable uploads: rclone can resume mid-file if the session is still valid |
| OneDrive | Resumable uploads: similar to Google Drive |
| Backblaze B2 | Large file parts: incomplete uploads are visible in B2 console |
For S3 orphaned multipart uploads: These accumulate and cost money. Clean them up using:
- RcloneView Terminal:
rclone cleanup s3-remote:bucket-name - Or via the AWS console under S3 → Your Bucket → Multipart uploads
Step 4 — Use --retries and --low-level-retries
For jobs that fail on transient errors, configure RcloneView's job to retry automatically:
Add these to the Custom flags field:
--retries 5 --retries-sleep 10s --low-level-retries 20
--retries 5— retry the entire job up to 5 times if errors occur--retries-sleep 10s— wait 10 seconds between retries--low-level-retries 20— retry individual low-level operations (API calls) up to 20 times
Step 5 — Handle Checksum Mismatches
After an interrupted transfer, re-running with checksum verification ensures data integrity:
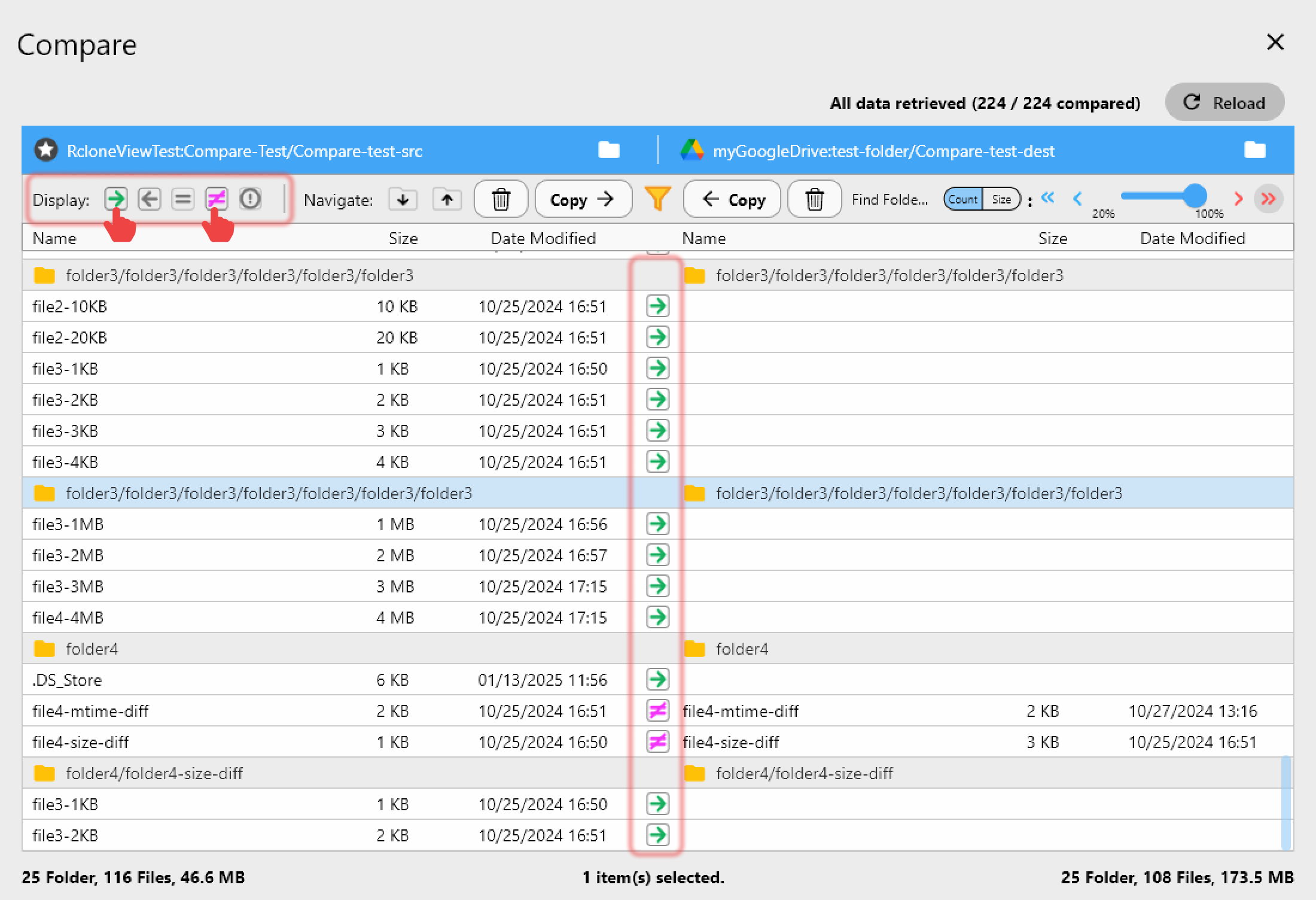
In RcloneView, enable Checksum verification in the job settings. This forces rclone to compare file contents (not just size/mtime) — slower, but guarantees that partially written files are caught and re-transferred.
Step 6 — Recover from a Sync That Deleted Files
If a Sync job ran in the wrong direction — copying the destination over the source instead of the other way around — you need to recover from cloud provider versioning:
- Google Drive: Restore from Trash or version history (available for 30–180 days).
- OneDrive: Restore from Recycle Bin or version history.
- S3 with versioning: Restore from a previous version in the S3 console.
- Backblaze B2: Restore from version history if enabled.
This is why using Copy mode (non-destructive) for initial large transfers is strongly recommended over Sync.
Prevention: Configure Transfers for Resilience
Build resilience into your transfer jobs from the start:
| Setting | Recommendation |
|---|---|
| Job mode | Use Copy for initial migrations; Sync for ongoing maintenance |
| Retries | Set --retries 5 --retries-sleep 10s |
| Checksum | Enable for critical data |
| Transfers | Lower concurrent count for unstable connections |
| Schedule | Run during stable network windows (overnight, off-VPN) |
| Bandwidth | Set limits to prevent timeouts caused by network saturation |
Getting Started
- Download RcloneView from rcloneview.com.
- Check Job History to identify what failed and why.
- Re-run the job — rclone skips completed files automatically.
- Configure retries and checksum verification for future resilience.
Most interrupted transfers require nothing more than clicking Run again. Rclone does the rest.
Related Guides:
- Avoid Data Loss from Wrong Sync Direction
- Checksum-Verified Cloud Migrations
- Accelerate Large Cloud Transfers