Transfer Files Between Google Cloud Storage and AWS S3 Without CLI Using RcloneView
Managing data across Google Cloud Storage and AWS S3 usually means juggling gsutil, aws cli, and custom scripts. RcloneView lets you do it all from a visual interface — browse, compare, sync, and schedule transfers between GCS and S3 in minutes.
Multi-cloud is the reality for most engineering teams. Your ML training data sits in GCS buckets, your production assets are on S3, and someone needs to keep them synchronized. The traditional approach — writing shell scripts with gsutil and aws cli — works, but it's fragile, hard to monitor, and impossible for non-engineers to manage.
RcloneView connects to both GCS and S3 natively, giving you a unified GUI to browse, transfer, compare, and automate data movement between the two biggest cloud platforms.
Manage & Sync All Clouds in One Place
RcloneView is a cross-platform GUI for rclone. Compare folders, transfer or sync files, and automate multi-cloud workflows with a clean, visual interface.
- One-click jobs: Copy · Sync · Compare
- Schedulers & history for reliable automation
- Works with Google Drive, OneDrive, Dropbox, S3, WebDAV, SFTP and more
Free core features. Plus automations available.
Why Move Data Between GCS and S3?
Teams transfer data between Google Cloud Storage and AWS S3 for several common reasons:
Multi-cloud redundancy — Storing critical data on two major providers protects against provider-level outages and vendor lock-in. If one cloud goes down, your data is accessible from the other.
Cost optimization — GCS and S3 have different pricing for storage, egress, and operations. Moving cold data to whichever provider is cheaper for your usage pattern can save significant money.
Cross-platform workflows — Your data science team uses GCP (BigQuery, Vertex AI), but your production infrastructure runs on AWS. Data needs to flow between both.
Migration — Moving from GCP to AWS (or vice versa) without downtime requires reliable, resumable transfers.
Compliance and data residency — Some regulations require data copies in specific regions or providers.
Setting Up GCS and S3 Remotes
Add Google Cloud Storage
- Open RcloneView and click Add Remote.
- Select Google Cloud Storage from the provider list.
- Choose your authentication method:
- Service Account JSON — Recommended for server-to-server transfers. Upload your service account key file.
- OAuth (browser login) — Good for personal GCP accounts. Follow the OAuth login guide.
- Set your project ID and default bucket location if prompted.
- Save the remote — your GCS buckets are now browsable.
Add AWS S3
- Click Add Remote again.
- Select Amazon S3 from the provider list.
- Enter your Access Key ID and Secret Access Key.
- Select your region and endpoint.
- Save — your S3 buckets appear in the Explorer.
For detailed S3 setup, see the AWS S3 connection guide.
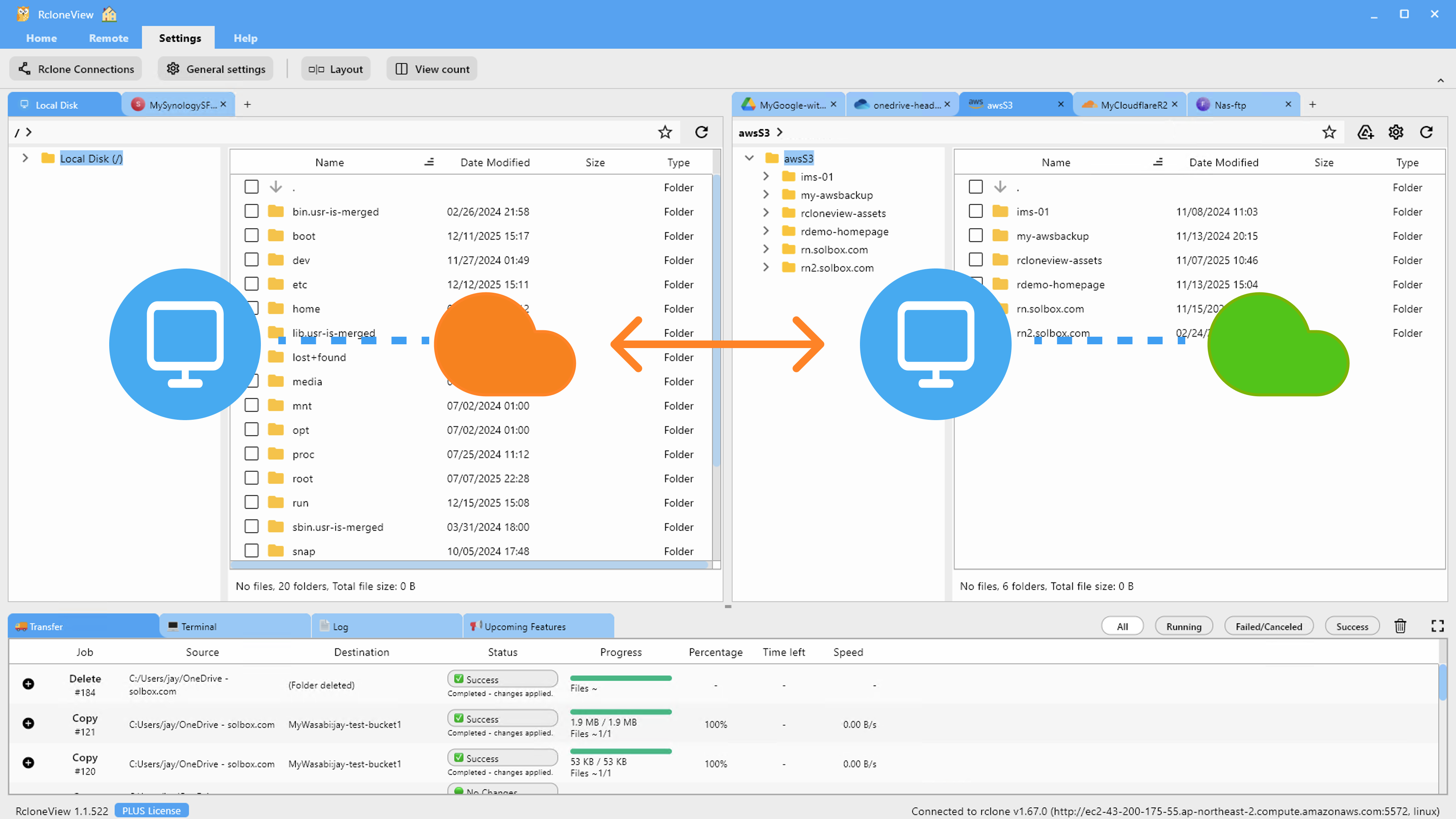
Browsing GCS and S3 Side by Side
Once both remotes are connected, open them in RcloneView's two-pane Explorer. GCS buckets on the left, S3 buckets on the right (or vice versa). You can:
- Navigate through buckets and folders on both sides simultaneously.
- View file sizes, dates, and counts to understand what's where.
- Drag and drop files directly from GCS to S3 — or use the built-in copy/move commands.
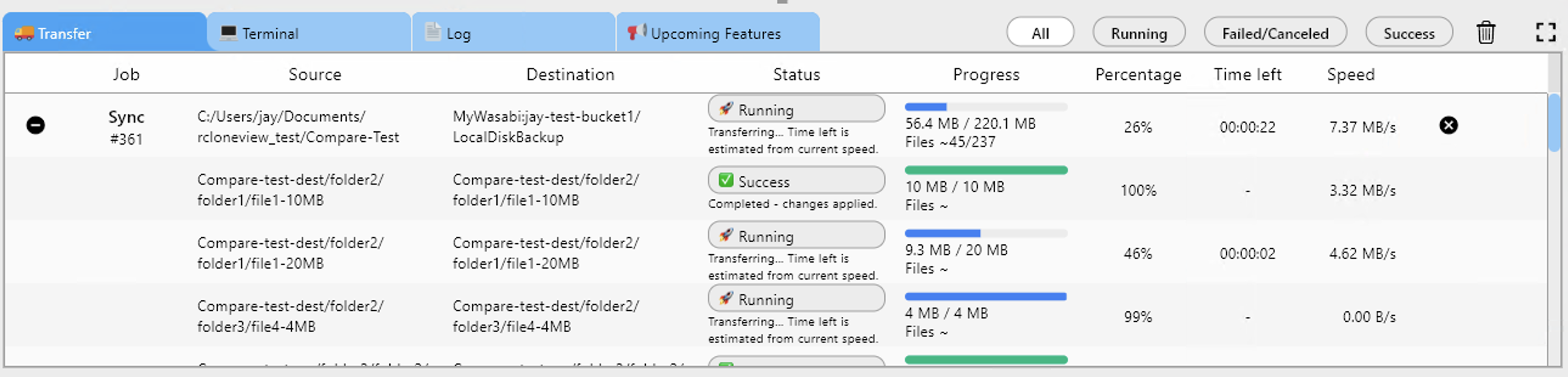
This side-by-side view gives you instant visibility into both clouds without switching between the GCP Console and AWS Console.
Transfer Scenarios
Scenario 1: One-Time Migration (GCS → S3)
Moving all data from GCS to S3 for a platform migration:
- Create a Copy job:
- Source: GCS remote → select your bucket
- Destination: S3 remote → select target bucket
- Configure for maximum speed:
- Parallel transfers: 8–16 (both GCS and S3 handle high parallelism well)
- Chunk size: 64MB–128MB for large files
- Enable
--fast-listflag to speed up directory listing
- Run the job and monitor progress in real time.
For large migrations, run the Copy job multiple times. After the first full copy, subsequent runs only transfer new or changed files — making it safe to resume if interrupted.
Scenario 2: Ongoing Sync (Bidirectional)
Keeping a GCS bucket and S3 bucket in sync continuously:
- Create a Sync job (GCS → S3) for the primary direction.
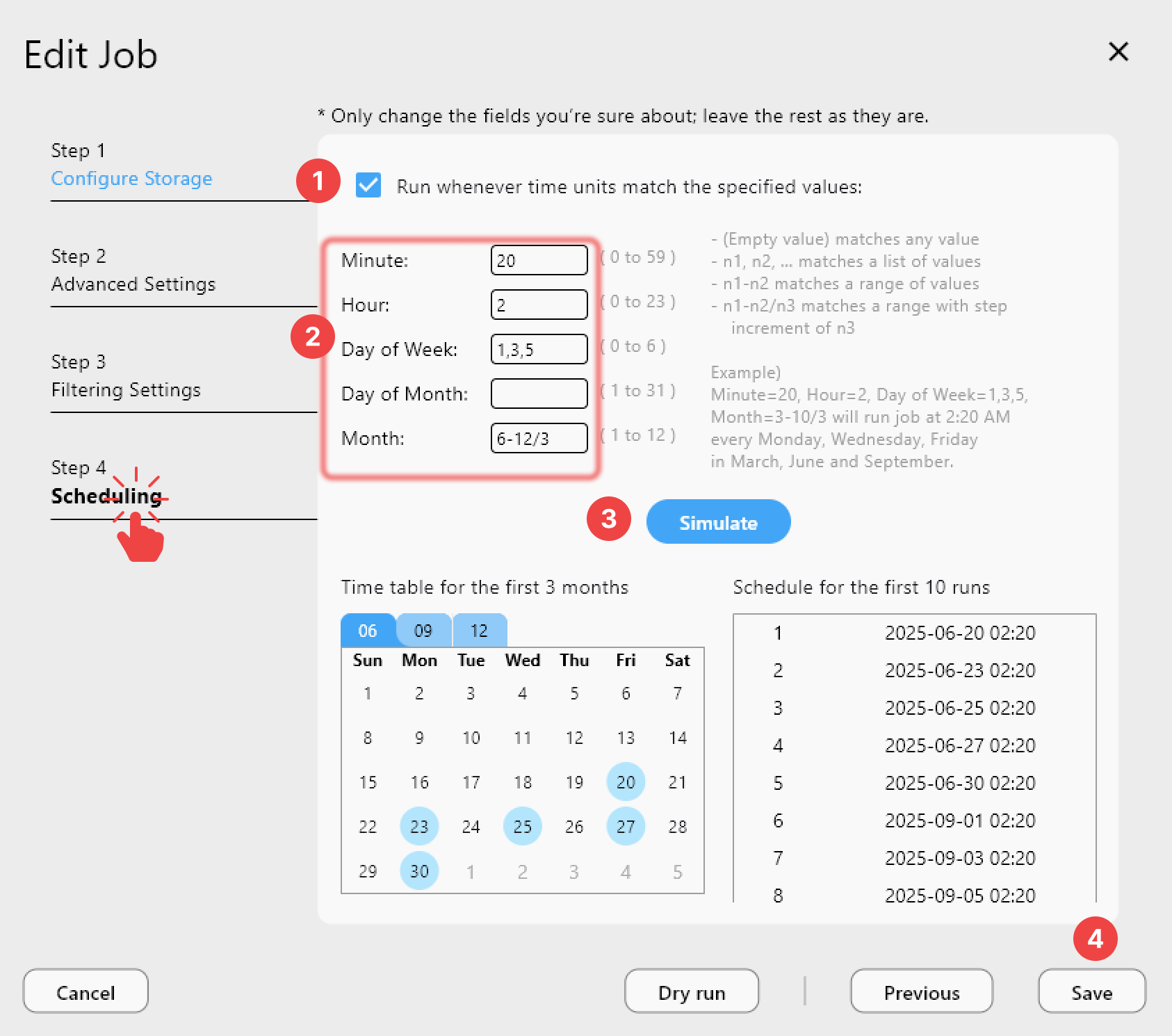
- Schedule it to run hourly or daily using Job Scheduling.
- Add a reverse Sync job (S3 → GCS) if you need bidirectional sync.
- Use Batch Jobs (v1.3) to run both directions in sequence.
Scenario 3: Selective Cross-Cloud Backup
Back up only specific data to the other cloud:
- Use Filter Rules to include/exclude specific file types or folders.
- Example: Only sync
*.parquetand*.csvfiles (ML datasets) - Example: Exclude
tmp/andlogs/directories
- Example: Only sync
- Create a scheduled Copy job with these filters applied.
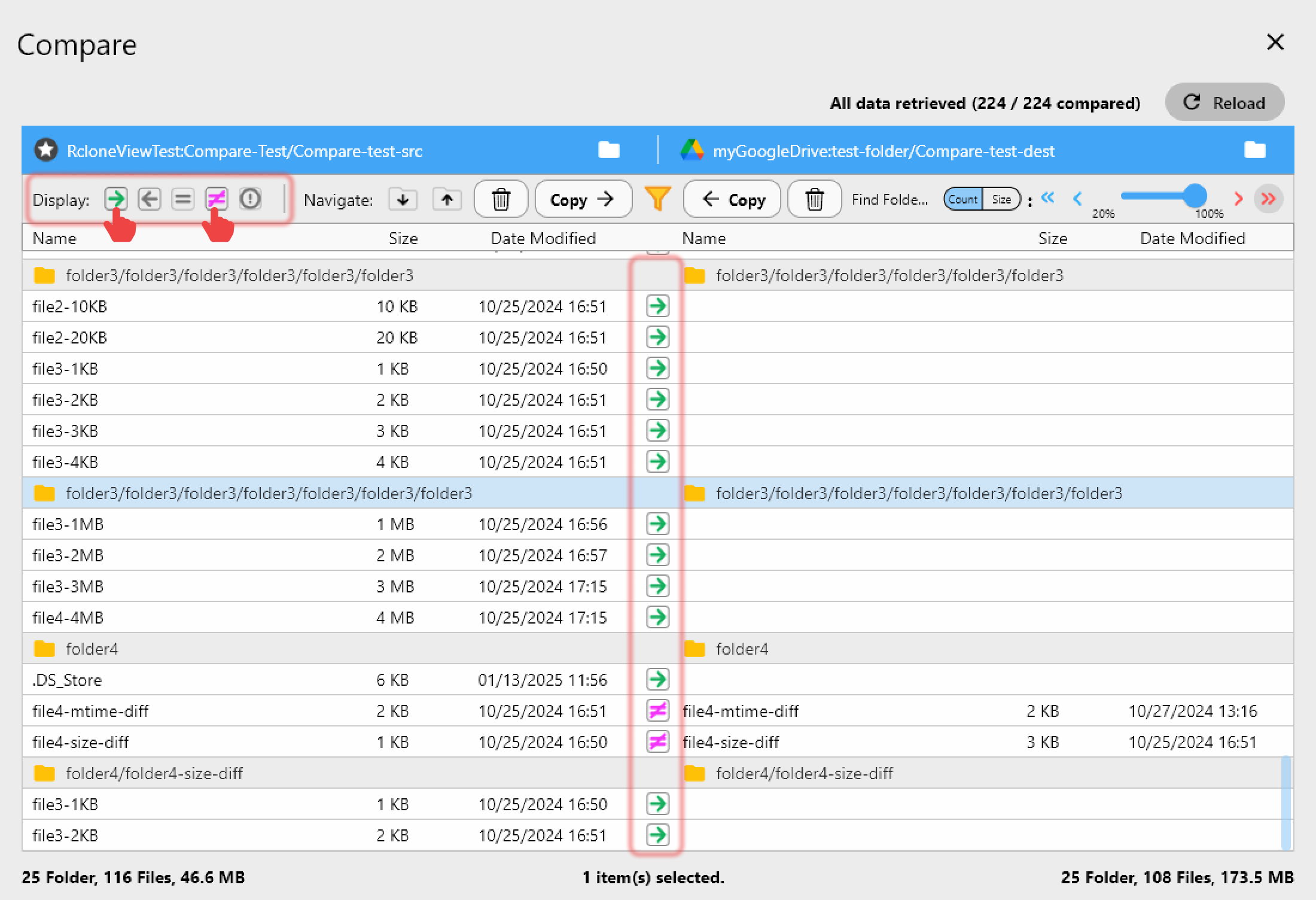
Comparing GCS and S3 Contents
Before and after transfers, use Folder Comparison to verify that both buckets contain the same data:
- Files only in GCS — Highlighted for easy identification.
- Files only in S3 — Shows what exists at the destination but not the source.
- Different files — Files with the same name but different sizes or checksums.
- Identical files — Confirmed matches across both clouds.
This is invaluable for migration verification: after copying terabytes of data, you can prove that every file arrived intact.
Optimizing Transfer Speed
GCS and S3 are both high-performance object stores, so you can push transfers hard:
| Setting | Recommended Value | Why |
|---|---|---|
| Parallel transfers | 8–16 | Both providers handle concurrent requests well |
| Chunk size | 64MB–128MB | Reduces API overhead for large files |
| Checkers | 16–32 | Speeds up the comparison phase for large directories |
| Buffer size | 128MB | Smooths out network latency between cloud regions |
| Fast-list | Enabled | Dramatically reduces API calls for directory listing |
Cross-region considerations
If your GCS bucket is in us-central1 and your S3 bucket is in eu-west-1, data must traverse the internet between regions. For best performance:
- Keep source and destination in the same geographic area when possible.
- Run transfers during off-peak hours to avoid network congestion.
- Monitor egress costs — both GCS and S3 charge for data leaving their networks.
Automating GCS ↔ S3 Workflows
Daily data pipeline
Set up a scheduled job that runs every night:
- Sync new ML training data from GCS → S3 for AWS-based training jobs.
- Copy results back from S3 → GCS for BigQuery analysis.
- Get notified via Slack when the pipeline completes.
Disaster recovery replication
Maintain a live copy of critical S3 data in GCS (or vice versa):
- Create a Sync job from your primary bucket to the DR bucket.
- Schedule it hourly for RPO (Recovery Point Objective) under 1 hour.
- Use checksum verification to ensure data integrity.
Cost-based tiering
Move data to whichever provider is cheaper for its access pattern:
- Frequently accessed data → Keep on the provider closest to your compute.
- Cold/archive data → Move to GCS Nearline/Coldline or S3 Glacier based on pricing.
- Schedule periodic tiering jobs to keep costs optimized.
GCS vs S3: Using RcloneView as a Unified Layer
Instead of learning two different CLIs (gsutil for GCS, aws s3 for S3), RcloneView gives you a single interface for both. This means:
- One tool to learn — Your team doesn't need to master two different command-line interfaces.
- Visual operations — Drag-and-drop, right-click menus, and dialog-based configuration instead of flags and arguments.
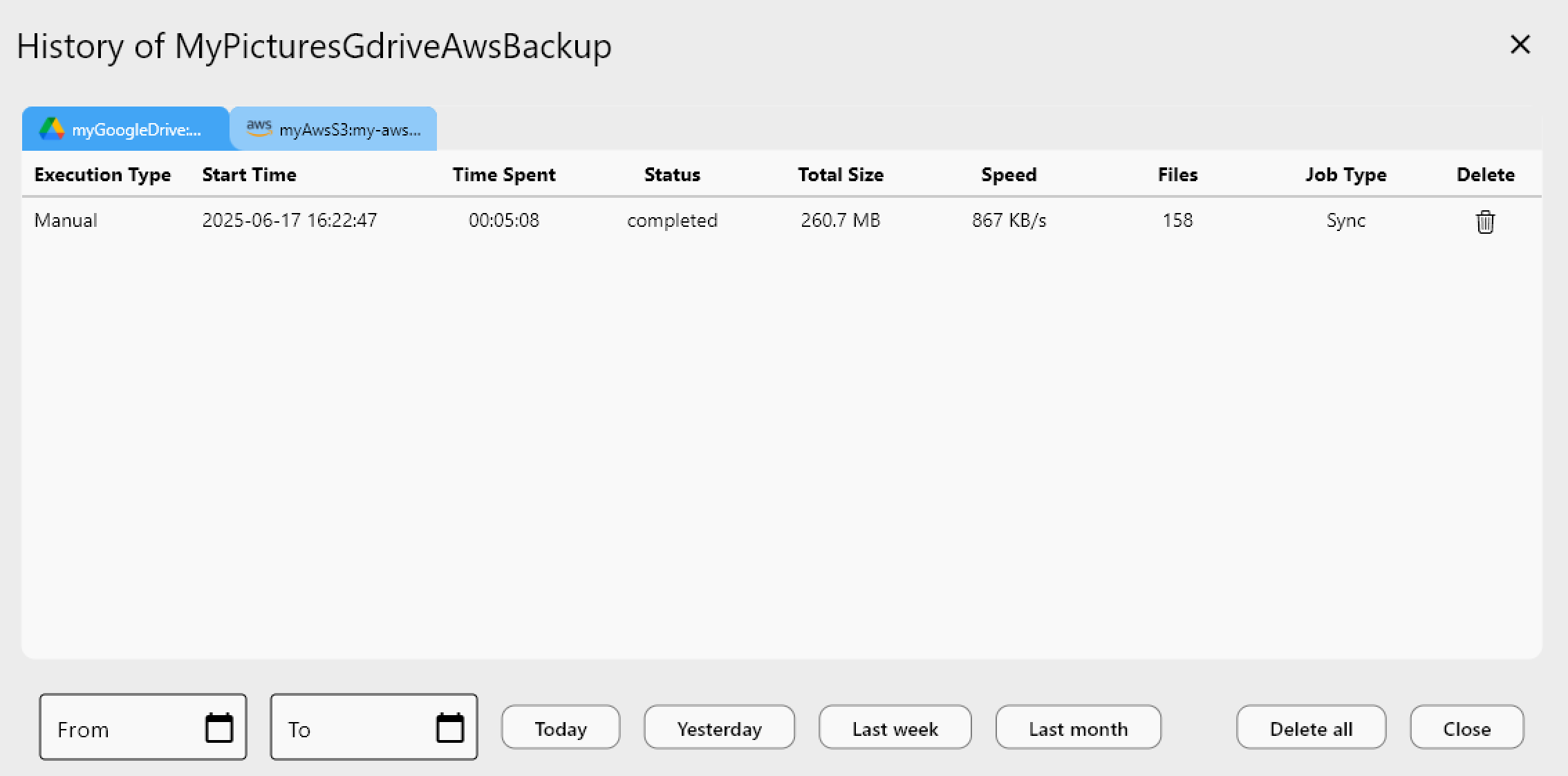
- Consistent monitoring — Same Job History and Transfer Monitoring regardless of which clouds are involved.
- Portable jobs — A job that syncs GCS to S3 works exactly the same way as one that syncs OneDrive to Dropbox.
Getting Started
- Download RcloneView from rcloneview.com (Windows, macOS, Linux).
- Add your GCS remote with a service account key or OAuth login.
- Add your S3 remote with access key credentials.
- Browse both side by side in the Explorer.
- Create a Copy or Sync job for your use case.
- Schedule and monitor for hands-free multi-cloud data management.
Stop juggling gsutil and aws cli. RcloneView unifies GCS and S3 management into one visual workflow — making multi-cloud data transfers accessible to your entire team, not just the engineers who know the CLI.
Related Guides:
- Add AWS S3 and S3-Compatible
- Add Remote via Browse-based Log-in (OAuth)
- Compare Folder Contents
- Create Sync Jobs
- Job Scheduling
- Real-time Transfer Monitoring
- Checksum Verified Cloud Migrations